
Imagine a world where your devices connect seamlessly and process data in real time, delivering instant insights. In today’s rapidly evolving technological landscape, this isn’t just a vision of the future; it’s the reality brought to life by distributed inference. Distributed inference, a critical component of modern computing, is reshaping how enterprises operate by enhancing efficiency, reducing latency, and bringing computing power closer to where it’s needed most—the edge.
As enterprises continue to embrace digital transformation, the need for faster, more efficient data processing becomes paramount. Distributed inference offers a solution by allowing machine learning models to be deployed across various environments, ensuring that data is processed locally, in real time. But what does this mean for businesses? How does it impact different industries? This blog will explore the significant benefits of distributed inference, showcasing its role in optimizing operations across various sectors.
Read More: NLP in Business: 10 Top NLP Algorithms
What is Distributed Inference?
Distributed inference refers to the process of executing machine learning models across multiple physical or cloud-based environments. Unlike traditional inference methods, which rely on centralized data processing, distributed inference allows computations to be performed closer to where the data is generated. This decentralized approach enables faster decision-making, particularly in applications where real-time processing is critical.
Functionality
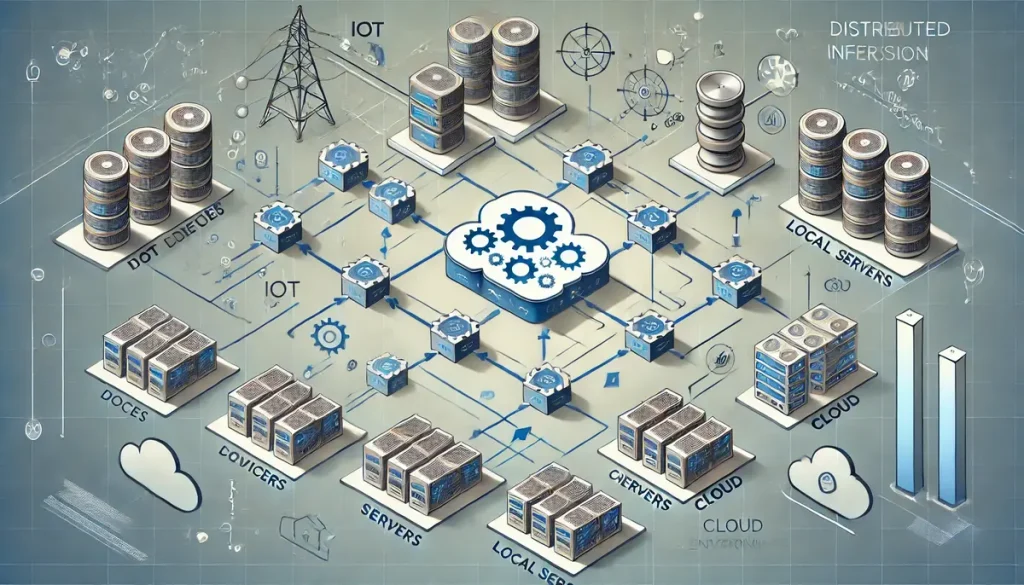
At its core, distributed inference involves deploying machine learning models across various nodes, including edge devices, local servers, and cloud environments. These nodes work together to process data locally, reducing the need to transmit large volumes of data to a central server. This setup not only enhances speed but also allows for more efficient use of resources, as each node can handle specific tasks based on its capacity and proximity to the data source.
Benefits Overview
Distributed inference offers several compelling benefits for modern enterprises:
- Reduced Latency: By processing data locally, distributed inference significantly cuts down on the time it takes to analyze and respond to information.
- Lower Bandwidth Costs: Minimizing data transfer to central servers reduces bandwidth usage and associated costs.
- Improved Data Privacy: Keeping data processing local enhances privacy by reducing exposure to potential breaches.
How Distributed Inference Works
Distributed Inference Architecture
Decentralized Architecture
- Distributed Nodes: The core of distributed inference lies in its decentralized nature, where multiple computing nodes are deployed across various environments such as edge devices, local servers, and cloud platforms. Each node operates independently to perform specific tasks, reducing the reliance on a central server.
- Task Allocation: Tasks are allocated based on the node’s capabilities, proximity to the data source, and the specific requirements of the application. This ensures that each node is used optimally, enhancing overall system efficiency.
Central Coordination
- Central System Management: A central system or cloud-based server typically manages the coordination among distributed nodes, ensuring that tasks are distributed effectively and that results are synchronized.
- Scalability: The architecture is highly scalable, allowing for the easy addition of more nodes to handle increased workloads or more complex tasks without significant performance degradation.
Data Processing Flow in Distributed Inference
Edge Data Generation
- Local Data Collection: Data is generated or collected at the edge, such as by sensors in IoT devices or user interactions on a mobile device. This data is crucial for real-time applications that require immediate processing.
- Preprocessing at the Edge: Before the data is fully processed, it undergoes preprocessing at the edge to remove noise, normalize inputs, or extract relevant features, optimizing it for subsequent analysis.
Model Execution
- Initial Inference: Once preprocessed, the data is fed into a machine learning model deployed at the edge. This model performs initial computations, such as making predictions or identifying patterns, to generate quick insights.
- Centralized Aggregation: If deeper analysis is required, the results from edge nodes are aggregated at a central server. This aggregation allows for more complex models to process the combined data, refining the initial insights.
Communication Between Nodes
Low-Latency Networks
- Data Transmission: Efficient communication between nodes is critical for distributed inference. Low-latency networks facilitate the rapid transfer of data and results between nodes, minimizing delays in the processing pipeline.
- Standardized Protocols: Nodes communicate using standardized protocols designed to handle distributed computing. These protocols ensure consistent data synchronization, preventing discrepancies across the network.
Robust Communication Mechanisms
- Redundancy: To mitigate potential network failures, redundancy is built into the communication mechanisms. Multiple nodes may perform the same task, ensuring that the system remains operational even if one node fails.
- Fault Tolerance: Distributed inference systems are designed to be fault-tolerant, with mechanisms in place to detect and recover from communication breakdowns, maintaining the integrity of the data processing flow.
Model Deployment Strategies
Edge-Only Deployment
- Independent Operation: In some cases, machine learning models are fully deployed at the edge, allowing devices to operate independently of the central system. This is ideal for applications requiring ultra-low latency, such as autonomous vehicles or real-time monitoring systems.
- Resource Efficiency: Deploying models at the edge reduces the need for constant communication with the cloud, conserving bandwidth and reducing operational costs.
Hybrid Deployment
- Split Model Execution: A hybrid approach involves splitting model execution between the edge and the cloud. For example, lightweight computations may be performed at the edge, while more complex tasks are handled by the cloud, balancing efficiency and computational power.
- Adaptive Deployment: The deployment strategy can be adapted based on the specific needs of the application. For instance, during peak usage, more tasks can be shifted to the cloud, while routine tasks are handled locally.
Data Synchronization and Model Updates
Real-Time Data Synchronization
- Continuous Data Flow: In distributed inference, data is continuously synchronized across nodes to ensure consistency. This synchronization can be done in real-time, particularly in applications where the latest data is critical for decision-making.
- Aggregation of Insights: The central system may aggregate insights from various nodes, combining them to form a comprehensive understanding of the situation. This aggregated data can then be used for more informed decision-making.
Model Update Mechanisms
- Centralized Model Management: Updates to machine learning models are typically managed centrally. When a new version of a model is available, it is distributed to all relevant nodes to ensure uniformity across the system.
- Rolling Updates: To minimize disruption, updates may be rolled out incrementally, with only a subset of nodes receiving the update at any given time. This approach reduces the risk of system downtime during the update process.
Security Considerations
Data Encryption
- Secure Data Transmission: All data transmitted between nodes is encrypted to prevent unauthorized access. Encryption protocols are implemented to protect the data during its journey from the edge to the cloud and back.
- Local Data Protection: In addition to secure transmission, data stored at the edge is also encrypted, ensuring that even if a device is compromised, the data remains inaccessible to unauthorized parties.
Access Controls
- Node Authentication: Each node in the distributed inference system is authenticated before it can participate in data processing. This ensures that only trusted devices can contribute to the network.
- User Access Management: Access controls are implemented to manage who can access the data and models. Only authorized personnel are granted access, reducing the risk of data breaches.
Key Benefits of Distributed Inference for Enterprises
Enhanced Computational Efficiency
Local Data Processing
One of the standout features of distributed inference is its ability to process data locally. This localized approach is particularly beneficial for applications requiring real-time decision-making. For instance, in IoT devices or autonomous vehicles, the ability to process data on-site rather than relying on cloud servers ensures immediate response times. This reduction in latency is crucial for applications where even a slight delay could lead to suboptimal outcomes.
Real-time Applications
Distributed inference is a game-changer for real-time applications. Voice recognition systems, smart home devices, and industrial automation are just a few examples where distributed inference enhances performance. By processing data at the edge, these systems can deliver instantaneous feedback, improving user experience and operational efficiency.
Improved Data Privacy and Security
Data Localization
Processing data locally not only improves speed but also enhances security. By keeping data within the device or local environment, distributed inference minimizes the risk of data breaches during transmission. This is especially important in sectors like healthcare and finance, where data sensitivity is paramount.
Compliance with Data Laws
With growing concerns about data sovereignty and international data laws, distributed inference provides a solution that aligns with these regulations. By enabling data processing within specific geographical boundaries, enterprises can ensure compliance with local laws, avoiding legal complications and enhancing trust with customers.
Scalability and Flexibility
Scalable Systems
Distributed inference systems are inherently scalable. Enterprises can add more nodes to the network as needed, allowing the system to handle increased workloads without a significant drop in performance. This scalability is particularly valuable in dynamic environments where demand can fluctuate, such as e-commerce platforms during peak shopping seasons.
Flexible Architecture
The flexibility of distributed inference architecture allows enterprises to adjust resources based on current needs. Whether it’s reallocating processing power during high-demand periods or optimizing resources for specific tasks, this adaptability ensures that systems remain robust and reliable. The ability to fine-tune operations in real time is a significant advantage for businesses aiming to maintain consistent service levels.
Examples of Distributed Inference Deployment
Telecommunications: Optimizing Network Operations
Use Case
In the telecommunications industry, distributed inference is being used to optimize network operations. By deploying machine learning models across network nodes, telecom providers can perform real-time analytics on network traffic, identifying potential issues before they escalate. This proactive approach helps in maintaining network reliability and reducing downtimes.
Benefits
The primary benefits of distributed inference in telecommunications include improved customer service through faster issue resolution and reduced operational costs by minimizing downtime. By processing data closer to the source, telecom providers can offer more reliable and responsive services to their customers.
Retail: Enhancing Customer Experience
Use Case
In the retail sector, distributed inference is revolutionizing how businesses interact with customers. By deploying machine learning models in stores, retailers can analyze customer behavior in real time, providing personalized shopping experiences. For example, smart shelves equipped with sensors can detect customer preferences and suggest relevant products, enhancing the overall shopping experience.
Benefits
The benefits of distributed inference in retail extend beyond customer satisfaction. By offering personalized recommendations and optimizing inventory management, retailers can boost sales and reduce waste. The ability to respond to customer needs in real time also fosters brand loyalty and encourages repeat business.
Healthcare: Improving Patient Outcomes
Use Case
In healthcare, distributed inference is being used to monitor patient data in real time. Hospitals and clinics deploy machine learning models at the edge to analyze vital signs and other health indicators, allowing for timely interventions. This real-time monitoring can be the difference between early detection of a critical condition and a delayed response.
Benefits
The benefits of distributed inference in healthcare are profound. Timely interventions lead to improved patient outcomes, while the ability to process data locally enhances data privacy. Additionally, distributed inference can help healthcare providers comply with stringent data protection regulations by keeping sensitive information within the facility.
Manufacturing: Boosting Production Efficiency
Use Case
Manufacturing is another sector benefiting from distributed inference. By deploying machine learning models on the production line, manufacturers can monitor equipment performance and predict maintenance needs. This predictive maintenance approach helps in reducing downtime and optimizing production efficiency.
Benefits
The advantages of distributed inference in manufacturing include increased productivity, reduced maintenance costs, and minimized downtime. By processing data on-site, manufacturers can quickly identify and address potential issues, ensuring that production remains smooth and efficient.
Implementing Distributed Inference in Your Tech Stack
Choosing the Right Architecture
Edge vs. Cloud
When implementing distributed inference, choosing the right architecture is crucial. Enterprises must consider whether to process data at the edge, in the cloud, or a combination of both. Edge processing is ideal for applications requiring low latency, such as IoT networks, while cloud processing is better suited for data-heavy operations that need significant computational power.
Guidance
Understanding where and how data is generated and processed can inform architecture choices. Enterprises should evaluate their specific needs and choose an architecture that aligns with their operational goals. This ensures that they maximize the benefits of distributed inference while maintaining a balance between performance and cost.
Integrating with Existing Systems
Seamless Integration
To reap the full benefits of distributed inference, it must integrate seamlessly with existing IT infrastructure. This integration requires careful planning to ensure compatibility between new and existing systems. Enterprises should assess their current setup and identify potential challenges in integrating distributed inference technologies.
Compatibility
Choosing hardware and software that complement existing systems is key to successful integration. Enterprises should prioritize solutions that offer flexibility and scalability, ensuring that distributed inference can be smoothly incorporated without disrupting ongoing operations.
Prioritizing Data Governance
Data Governance Importance
As data is processed across distributed nodes, robust data governance practices become essential. Enterprises must establish clear protocols for data access, processing, and storage to ensure that data remains secure and compliant with relevant regulations.
Protocols
Implementing distributed inference requires careful consideration of data governance protocols. Enterprises should develop guidelines for data management, including who can access data, how it is processed, and where it is stored. This not only ensures compliance with data protection laws but also enhances overall data security.
Conclusion
Distributed inference is rapidly becoming a cornerstone of modern enterprise operations. By enabling faster, more efficient data processing, it offers significant advantages in terms of computational efficiency, data privacy, scalability, and flexibility. As we’ve seen, its impact is already being felt across various industries, from telecommunications to healthcare.
For businesses looking to stay competitive, integrating distributed inference into their tech stack is not just an option—it’s a necessity. By carefully choosing the right architecture, ensuring seamless integration, and prioritizing data governance, enterprises can harness the full potential of distributed inference.